Język SQL, pomimo ściśle ustalonego szyku bloków logicznych (SELECT, FROM, WHERE…. ) jest dość elastyczny. W rozdziałach dotyczących elementów składniowych zapytań, do znudzenia podkreślałem fundament na którym zbudowane są relacyjne bazy danych i SQL. Jest to matematyczna teoria zbiorów. Podzapytania idealnie obrazują te zasady w praktyce i są często stosowanymi konstrukcjami.
Podzapytania, jak sama nazwa wskazuje, są częścią podrzędną innego zapytania. Możemy podzielić je na dwie kategorie ze względu na powiązanie z kwerendą nadrzędną :
- niezależne – funkcjonować mogą w całkowicie oderwanym kontekście. Można je uruchomić jako osobne kwerendy – o nich właśnie jest ten artykuł.
- skorelowane – są bezpośrednio powiązane z zapytaniem nadrzędnym. Opisuję je w kolejnym rozdziale tego kursu.
Podzapytania niezależne
Przypomnijmy podstawowe zasady, które intuicyjnie nakierowują na właściwie tory jeśli chodzi o temat podzapytań. Jeśli przerabiasz ten kurs od początku, reguły te powinny być dla Ciebie już oczywiste.
Każde zapytanie SQL to operacja na zbiorze lub zbiorach elementów. Tabele i widoki do których zazwyczaj odwołujemy się w kwerendach to tylko przykłady zbiorów. Wynikiem działania dowolnej kwerendy jest także zbiór.
Rozważmy na przykład zapytanie do zbioru elementów (tabeli) dbo.Customers. Wybierzemy tylko takie elementy (rekordy), dla których wartość atrybutu (kolumny) City, jest równa ciągowi znaków 'London’.
USE Northwind
GO
SELECT CompanyName, City, Country
FROM dbo.Customers
WHERE City = 'London'

To co chciałem na tym banalnym przykładzie podkreślić, to fakt że zapytanie, odwołuje się do zbioru (lub zbiorów) i zwraca jeden zbiór. Skoro więc zwraca zbiór, to możemy ten zbiór także odpytywać jak zwykłą tabelę. Będzie to pierwszy przykład z wykorzystaniem typowego podzapytania niezależnego we FROM :
SELECT *
FROM
(
-- wstępna, selekcja elementów i atrybutów zbioru dbo.Customers
-- może tu być dowolna skomplikowana kwerenda.
SELECT CompanyName, City, Country
FROM dbo.Customers
where City = 'London'
) AS MojePodzapytanie
WHERE CompanyName like '[A-C]%'
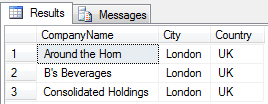
Zauważ, że w każdej chwili możesz to podzapytanie uruchomić zaznaczając tylko jego zakres. Jest ono niezależne w stosunku do zapytania zewnętrznego. Wykonane zostanie raz, w trakcie całego procesu logicznego przetwarzania tej kwerendy.
Każdy zbiór do którego odnosimy się we FROM musi być nazwany i w pełni określony. Stąd konieczność stosowania aliasów oraz unikalnych nazw kolumn w ramach podzapytań.
Miejsca w których możemy stosować podzapytania
Podzapytania możemy stosować praktycznie w dowolnym bloku logicznym kwerendy. Jedynym ograniczeniem jest rodzaj zwracanego zbioru. Musi pasować do miejsca w którym chcemy go użyć. Na przykład we FROM, może to być dowolny zbiór (jednoelementowy, wieloelementowy itd), z kolei w SELECT musi to być wartość skalarna czyli zbiór jednoelementowy opisany jednym atrybutem.
W dalszych przykładach, będę wykorzystywał bazę testową AdventureWorks2008, aby zaprezentować typowe zastosowania podzapytań w różnych miejscach kwerendy.
Pobierzemy informacje o zleceniach z czerwca 2014, z rejonu Wielkiej Brytanii (CountryRegionCode = 'GB’), dla których wartość (TotalDue), przekroczyła średnią liczoną dla wszystkich zleceń.
Zacznijmy od kwerendy, która zwróci nam informacje o średniej wartości dla wszystkich zamówień.
USE AdventureWorks2008
GO
SELECT AVG(TotalDue) as AVG_TotalDue
FROM [Sales].[SalesOrderHeader]
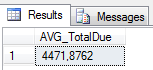
Zwracany zbiór jest szczególny. Jednoelementowy, opisany jednym atrybutem (jedną kolumną) – czyli to zwykła wartość skalarna.
Taki zbiór możemy umieścić w każdym miejscu kwerendy – jako podzapytanie. Najczęściej będziemy go stosować w warunkach WHERE lub w SELECT. Może być też stosowany w innych miejscach gdzie tworzymy wyrażenia, filtracji grup w HAVING czy warunki złączeń w ON.
Wykorzystajmy teraz te informacje, aby odfiltrować rekordy w WHERE i dodatkowo wyświetlić ją w SELECT jako wartość dodatkowej kolumny.
SELECT SalesOrderID, OrderDate, TotalDue, st.Name AS TerritoryName,
(
-- podzapytanie w SELECT – średnia dla wszystkich zleceń
SELECT AVG(TotalDue)
FROM [Sales].[SalesOrderHeader]
) AS AVG_TotalDue
FROM [Sales].[SalesOrderHeader] soh
inner join [Sales].[SalesTerritory] st ON soh.TerritoryID = st.TerritoryID
WHERE st.CountryRegionCode = 'GB' and OrderDate between '2004-06-01' and '2004-06-30'
and TotalDue >=
(
-- podzapytanie w filtracji w WHERE
SELECT AVG(TotalDue) AS AVG_TotalDue
FROM [Sales].[SalesOrderHeader]
)
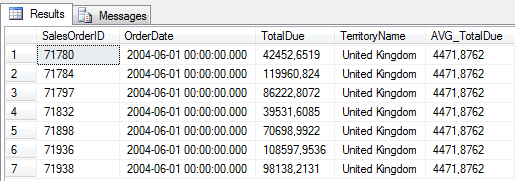
Warto podkreślić, że jeśli podzapytanie nie zwróciłoby tu żadnego rekordu, to wynikiem w kwerendzie zewnętrznej, będzie jeden element opisany NULLami. Trzeba mieć to na uwadze bo jeśli zdarzyłaby się taka sytuacja w podzapytaniu w WHERE – to otrzymamy pusty zbiór. Żaden z rekordów nie spełni przecież warunku TotalDue >= NULL. Każde porównanie z NULL to wartość nieznana, więc każdy rekord będzie odfiltrowany.
Usystematyzujmy dotychczasowe informacje. W SELECT może znaleźć się tylko takie podzapytanie, które zwraca wartość skalarną. We FROM możemy wykorzystać każde podzapytanie, definiujące jakikolwiek zbiór. Tworzenie warunków połączeń w ON , wyrażeń w WHERE oraz filtracji grup w HAVING, dopuszcza różne zbiorów w zależności od zastosowanych operatorów. Standardowo będą to operatory porównujące wartości skalarne ( =, <, >, <>, itd.) – wtedy tylko takie podzapytania, które zwracają skalar.
Są też specjalne operatory działające na zbiorach np. IN, ANY (SOME) , ALL. Operatory te, działają na wektorze wartości. Wektor to zbiór elementów opisanych jednym atrybutem (czyli wartości skalarnych). Zatem w tych przypadkach, podzapytania mogą zwracać wektor.
Pozostał jeszcze jeden specjalny operator – EXISTS / NOT EXISTS, który możemy stosować np. w WHERE. Za jego pomocą sprawdzamy tylko czy zbiór podzapytania jest pusty czy nie. W tym przypadku nie ma znaczenia jakiego typu są to elementy. Jeśli są, to zwracana jest wartość TRUE, jeśli nie – FALSE.
Podzapytania z operatorami IN, ANY (SOME), ALL
Weźmy za przykład kwerendę, która da nam informacje o wszystkich zleceniach, dla trzech najlepszych (pod względem generowania obrotów firmy) Klientów.
Najpierw skupmy się na podzapytaniu, które powinno zwrócić nam wektor 3-elementowy z identyfikatorami najlepszych Klientów. Trzech najdroższych nam Klientów otrzymamy za pomocą takiego zapytania :
SELECT TOP 3 CustomerID , SUM(TotalDue) as TotalSales
FROM [Sales].[SalesOrderHeader] soh
GROUP BY CustomerID
ORDER BY TotalSales DESC
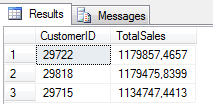
To jeszcze nie jest wektor, ale już coś. Jeśli spróbujemy teraz zbudować kwerendę w oparciu o takie podzapytanie, filtrując w WHERE z wykorzystaniem operatora IN :
SELECT SalesOrderID, OrderDate, TotalDue, CustomerID from [Sales].[SalesOrderHeader] soh
WHERE CustomerID in (
SELECT TOP 3 CustomerID , SUM(TotalDue) as TotalSales
FROM [Sales].[SalesOrderHeader] soh
GROUP BY CustomerID
ORDER BY TotalSales DESC
)
Otrzymamy komunikat o błędzie, ponieważ podzapytanie generuje niepoprawny zbiór (nie jest to wektor – posiada dwie kolumny).
Msg 116, Level 16, State 1, Line 9 Only one expression can be specified in the select list when the subquery is not introduced with EXISTS.
No to zróbmy z niego wektor – podzapytanie z podzapytania :
SELECT SalesOrderID, OrderDate, CustomerID
FROM [Sales].[SalesOrderHeader] soh
WHERE CustomerID IN (
-- podzapytanie z podzapytania w WHERE
SELECT CustomerID
FROM (
SELECT TOP 3 CustomerID , SUM(TotalDue) as TotalSales
FROM [Sales].[SalesOrderHeader] soh
GROUP BY CustomerID
ORDER BY TotalSales DESC
) AS WektorIdentyfikatorowKlientow
)
W powyższym przykładzie, widzimy inną ważną właściwość podzapytań – możliwość zagnieżdżania ich w sobie. Możemy tworzyć podzapytania z podzapytań do 32 poziomów.
Oczywiście można by było powyższą kwerendę zapisać inaczej, z zastosowaniem podzapytania we FROM.
SELECT SalesOrderID, OrderDate, soh.CustomerID
FROM [Sales].[SalesOrderHeader] soh INNER JOIN (
-- podzapytanie we FROM
SELECT TOP 3 CustomerID , SUM(TotalDue) as TotalSales
FROM [Sales].[SalesOrderHeader] soh
GROUP BY CustomerID
ORDER BY TotalSales DESC
) a on soh.CustomerID = a.CustomerID
Wynik i nawet plan wykonania w tej sytuacji będzie identyczny. Często filtracja w jak najwcześniejszym kroku procesu przetwarzania kwerendy przynosi lepsze rezultaty, choć nie zawsze.
Rozważmy bardziej skomplikowany przykład. Chcemy wyświetlić trzy najdroższe zamówienia dla trzech naszych najlepszych Klientów. Zapytanie to zapiszemy z zastosowaniem funkcji szeregującej RANK oraz funkcji okna OVER.
SELECT * FROM
(
SELECT SalesOrderID, TotalDue,
RANK() OVER(Partition by soh.CustomerID order by TotalDue desc) as Majority,
soh.CustomerID
FROM [Sales].[SalesOrderHeader] soh inner join
(
SELECT TOP 3 CustomerID , SUM(TotalDue) as TotalSales
FROM [Sales].[SalesOrderHeader] soh
GROUP BY CustomerID
ORDER BY TotalSales DESC
) b on soh.CustomerID = b.CustomerID
) a
WHERE Majority <= 3
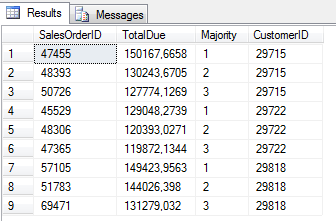
Inny sposób na osiągnięcie tego samego celu, z filtracją Klientów w WHERE.
SELECT *
FROM
(
-- wychwycenie tylko najdroższych zamówień per Klient
SELECT SalesOrderID, TotalDue,
RANK() OVER(Partition by CustomerID order by TotalDue desc) as Majority,
CustomerID
FROM [Sales].[SalesOrderHeader] soh
) a
WHERE Majority <= 3 AND CustomerID IN (
-- zrobienie wektora
SELECT CustomerID
FROM (
-- wychwycenie 3 najdroższych nam Klientów
SELECT TOP 3 CustomerID , SUM(TotalDue) as TotalSales
FROM [Sales].[SalesOrderHeader] soh
GROUP BY CustomerID
order by TotalSales desc
) a
)
To zapytanie generuje jednak bardziej kosztowny plan wykonania (w porównaniu do poprzedniego 31% : 69%).
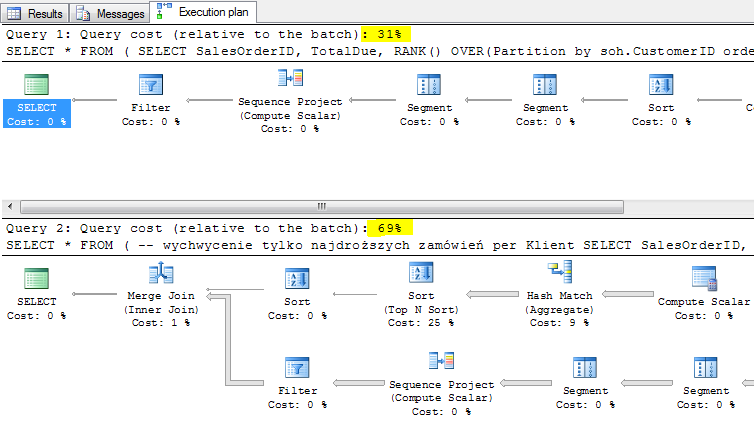
W SQL jest wiele sposobów na osiągnięcie tego samego rezultatu. Zagadnienia związane z wydajnością, poruszam w ostatnim rozdziale tego kursu.
Według mnie przykłady są bardzo dobre. Poczynając od prostych po trudniejsze. Stronka ogólnie mistrzowska, wszystko zrozumiałe i wytłumaczone w przeciwieństwie do treści w dokumentacjach poszczególnych komend. Jako student bardzo polecam do kolosa z baz danych.
Niestety podzapytania nie są zrozumiałe, bo Autor użył zbyt skomplikowanych przykładów. Natomiast pozostała część kursu opisująca podstawy SQL jest świetna, np. złączenia, operacje na zbiorach, itd. Przeglądnąłem kilka innych tutoriali i książek o SQL, i zazwyczaj właśnie złączenia i operacje na zbiorach są tam źle tłumaczone. Natomiast tutaj Autor użył świetnych przykładów i dydaktycznych obrazków dobrze tłumaczących ideę tych operacji.
Nie zgodzę się z tą opinią. Przykłady są świetne nie dlatego, że proste czy skomplikowane, ale dlatego, że są wzięte z życia.
Poza tym rozważanie alternatywnych kwerend, które mają ten sam skutek znakomicie rozwija umiejętności w SQLu. Po takim kursie potrafisz szerzej spojrzeć na zagadnienia bazodanowe.
Nie zrażaj się że czegoś nie pojmiesz za pierwszym razem. Czytaj inne rzeczy i wróć do tego trudniejszego tematu za jakiś czas. Nie jesteś wyjątkiem.
Powodzenia